728x90
반응형
import pandas as pd
# We create a list of Python dictionaries
items2 = [{'bikes': 20, 'pants': 30, 'watches': 35},
{'watches': 10, 'glasses': 50, 'bikes': 15, 'pants':5}]
pd.DataFrame(data=items2, index=['store 1','store 2'])
| 판다스의 2차원 데이터를 처리하는 "데이터프레임"에서 데이터를 액세스 하는 방법 3가지 1. 컬럼의 데이터를 가져오는 방법 : 변수명 오른쪽에 대괄호 사용 2. 사람 용인, 인덱스와 컬럼명으로 데이터 액세스 하는 방법 변수명.loc[ , ] 3. 컴퓨터용인 컴퓨터 인덱스로 데이터를 가져오는 방법 변수명.iloc[ , ] |
1. 컬럼의 데이터를 가져오는 방법 : 변수명 오른쪽에 대괄호 사용
df = pd.DataFrame(data=items2, index=['store 1','store 2'])
df['bikes']
df[['bikes','watches']]
2. 사람용(진한 글씨)인, 인덱스와 컬럼명으로 데이터 액세스 하는 방법, 변수명.loc[ , ]
스토어 1의 데이터를 가져오시오
df.loc['store 1', ]df.loc['store 1', : ] # [행(인덱스), 열(컬럼)]
스토어 1의 팬츠 데이터를 가져오시오
df.loc['store 1', 'pants']df['pants']['store 1'] # 컬럼 액세스
스토어1의 바이크와 와치 데이터를 가져오시오
df.loc['store 1',['bikes', 'watches']]
스토어 2에서 팬츠부터 글래시스까지 데이터를 가져오시오
df.loc['store 2','pants':'glasses']
3. 컴퓨터용인 컴퓨터 인덱스로 데이터를 가져오는 방법, 변수명.iloc[ , ]
스토어 1의 데이터를 가져오시오
df.iloc[0,] # 프로그래밍상 부여된 번호로 작성
스토어 1의 팬츠 데이터를 가져오시오
df.iloc[0, [0,2]]
스토어 1의 데이터 중 팬츠부터 글래시스까지 가져오시오
df.iloc[0, 1:]df.iloc[0, 1:2+1] # 리스트 뒷쪽에 +1 해줌, ex) 2번까지 불러오기df.loc['store 1', 'pants': 'watches']
데이터의 값 변경
스토어2의 시계 갯수를 20으로 변경하시오
df.loc['store 2', 'watches'] = df.loc['store 2', 'watches']+10
dfdf.loc['store 2', 'watches'] = 20
df
새로운 컬럼을 만드는 방법
shirts 라는 컬럼(열, 기둥)을 만들되, store 1에는 15, store 2에는 2로 저장하세요
df['shirts']= [15,2]
df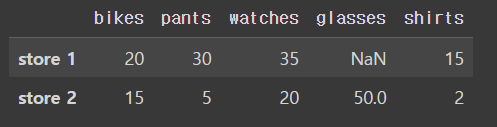
suits 라는 컬럼을 만들되, pants의 수와 shirts 수를 더해서 만드세요
df['pants']
df['shirts']
df['pants']+df['shirts']
df['suits'] = df['pants']+df['shirts']
df
행삭제, 열삭제 하는 방법
행삭제, store 1을 삭제하는 방법 / 변수명.drop( , )
df.drop('store 1', axis=0) # Axis(축) 2차원에서 행은 0, 열은 1
# df = df.drop('store 1', axis=0) -> 메모리에 저장
열삭제, watches 컬럼을 삭제하시오
df.drop('watches',axis=1)
bikes, glasses, suits 컬럼을 삭제하시오
df.drop(['bikes', 'glasses', 'suits'], axis =1)
인덱스나 컬럼명을 바꾸는 방법, 변수명.rename()
df.rename(index={'store 2' : 'last store'})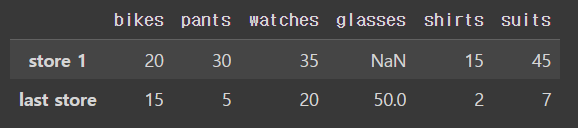
df.rename(columns={'bikes':'hats'})
컬럼을 인덱스로 사용하는 방법, 변수명.set_index(컬럼 이름)
가게 이름을 A,B 라고 하여 새로운 컬럼 name 컬럼을 만드세요
df['name']= ['A','B']
df

df.set_index('name')
df = df.set_index('name') # 메모리에 반영
df
다시 컬럼으로 만들고 싶다, 변수명.reset_index()
df.reset_index() # 기존에 있던 데이터는 이미 유실되어서 컴퓨터가 지정한 인덱스 번호로 바뀜
df = df[['watches', 'shirts', 'bikes', 'pants', 'suits', 'glasses']]
# 데이터를 가공하는데 컬럼의 순서는 생각보다 중요하지 않음(언제든지 변경가능)
df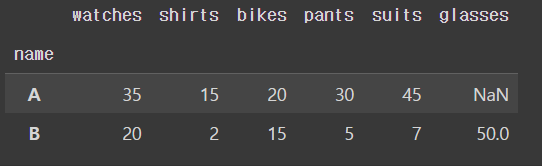
728x90
반응형
'즐거운프로그래밍' 카테고리의 다른 글
| [pandas] pandas 파일 읽어온 뒤 데이터 처리하기(describe, head, tail, info) (0) | 2023.11.15 |
|---|---|
| [pandas] pandas NaN (1) | 2023.11.14 |
| [pandas] pandas DataFrame 1 (0) | 2023.11.14 |
| [pandas] pandas Series 데이터 2 (1) | 2023.11.14 |
| [pandas] pandas Series 데이터 1 (0) | 2023.11.14 |