728x90
반응형
csv 파일 불러오기
df = pd.read_csv('/content/drive/MyDrive/Notebooks/data/company.csv')
df
중복된 데이터를 가지고 있는 컬럼들이 있다.
예를 들면, 성별과 같은 컬럼들 이런 데이터를 카테고리컬 데이터라고 한다.
유니크한 데이터의 갯수를 세는 방법
df['Year'].nunique() # nunique = number unique
데이터의 전체 갯수를 세는 방법
df['Year'].count()
중복제거한 유니크한 데이터를 표시
df['Year'].unique()
데이터 프레임 전체에 describe를 하면, 수치 데이터만 보여준다.
df.describe()
describe 함수를 문자열 데이터 컬럼 하나에만 적용하면, 빈도수 등을 알 수 있다.
df['Name'].describe()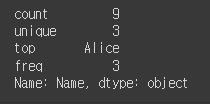
카테고리컬 데이터의 각 데이터별로 묶어서 처리하는 방법
각 연도별로 연봉 총합을 구하시오
df.groupby('Year')['Salary'].sum()
각 직원별로 해당 직원이 받은 연봉 평균은 얼마인가?
df.groupby('Name')['Salary'].mean()
연도별과 부서별로 연봉은 총 얼마씩 지급되었는가?
df.groupby(['Year','Department'])['Salary'].sum()
연도별 연봉의 총합과 최소값을 구하세요
df.groupby('Year')['Salary'].agg([np.sum, np.min])
연도별 연봉의 총합과 최소값, 평균값을 구하세요
df.groupby('Year')['Salary'].agg([np.sum, np.min, np.mean])
Name 컬럼의 사람이름은 각각 몇개씩 있는 파악하시오
직원의 이름별로 이름에 해당하는 데이터는 몇개씩 있는가?
df.groupby('Name')['Name'].count()df['Name'].value_counts()
728x90
반응형
'즐거운프로그래밍' 카테고리의 다른 글
| [pandas] pandas 데이터 가공 연습하기 (0) | 2023.11.15 |
|---|---|
| [pandas] pandas HTML 웹 자료 읽어온 후 데이터 처리 (0) | 2023.11.15 |
| [pandas] pandas 파일 읽어온 뒤 데이터 처리하기(describe, head, tail, info) (0) | 2023.11.15 |
| [pandas] pandas NaN (1) | 2023.11.14 |
| [pandas] pandas DataFrame 2 (0) | 2023.11.14 |