728x90
반응형
import pandas as pd
reviews = pd.read_csv('/content/drive/MyDrive/Notebooks/data/wine-data.csv',index_col=0)
reviews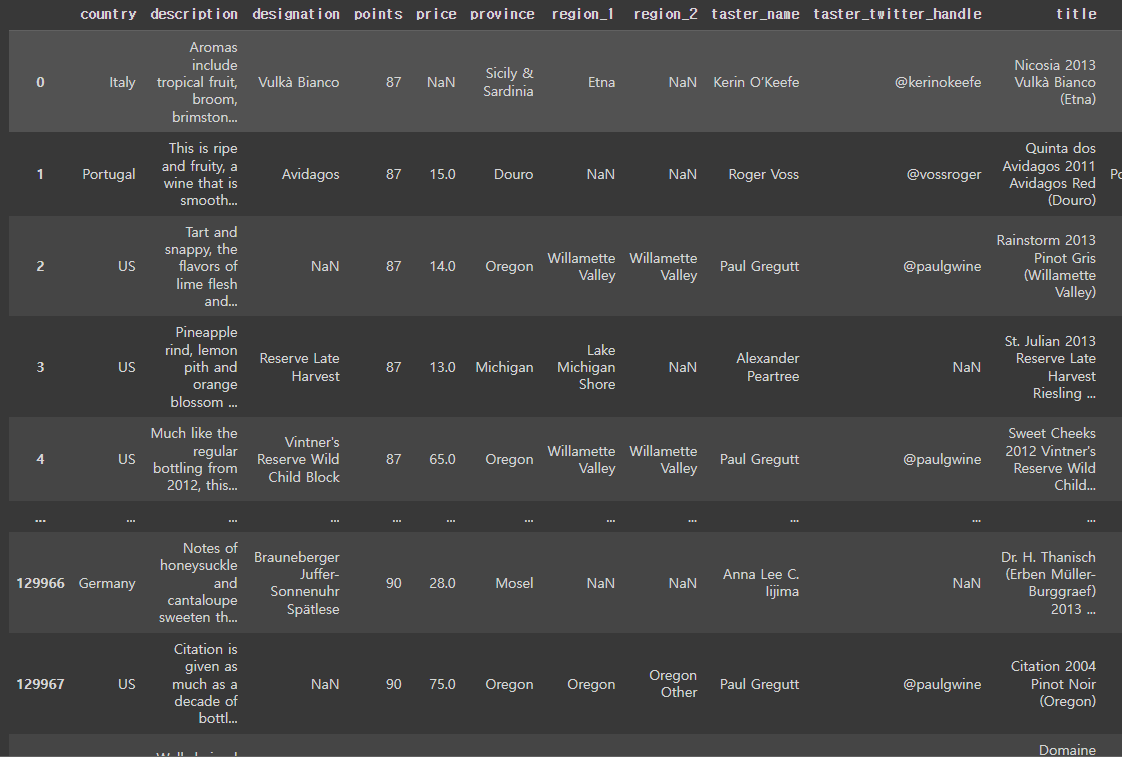
인덱스를 title 컬럼으로 셋팅한다.
reviews.set_index('title', inplace=True)
# inplace=True inplace:해당 장소에의 의미, 메모리에서 작업(반영)
reviews
먼저 데이터가 비어있느것이 있는지 확인한다.
reviews.isna()
reviews.isna().sum()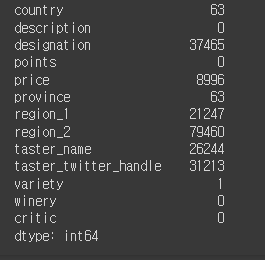
그리고나서, 가격이 없는 데이터는 빼고, 데이터셋을 가져온다.
reviews['price'].notna() # notna : true = 가격이 있음
reviews = reviews.loc[reviews['price'].notna(), ]
reviews
리뷰에 새로운 컬럼 critic 만들고, everyone 이라고 값 넣는다.
reviews['critic']='everyone'
reviews
리뷰의 포인트 컬럼은 수치로 되어있다. 이 컬럼의 기초통계데이터를 확인하시오. (평균, 최대 최소 등)
reviews['points'].describe()
taster_name 컬럼은 사람 이름으로 되어있다. 몇명의 사람들이 평가를 한것인까?
reviews['taster_name'].nunique()
reviews.groupby('taster_name')['taster_name'].count() # 테스터 네임 오름차순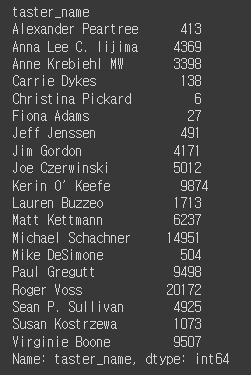
reviews['taster_name'].value_counts() # 인덱스 갯수 오름차순
리뷰 포인트의 평균을 구하시오
reviews['points'].mean()
테스터들의 이름을 전부 확인하시오
reviews['taster_name'].unique() # NaN 포함
reviews['taster_name'].unique().size # NaN 포함 갯수
reviews['taster_name'].dropna().unique().size # NaN 제거 후 갯수reviews['taster_name'].nunique()
각 테스터들은, 각각 몇개의 와인을 테스트 했는지 확인하시오. ( 테스터 이름, 갯수 )
reviews['taster_name'].value_counts()
리뷰의 포인트의 평균을 구하고, 리뷰의 포인트값이, 평균보다 큰 데이터 (즉, 평가가 좋은 와인) 만 가져오시오.
reviews.loc[reviews['points'] > reviews['points'].mean(), ]
728x90
반응형
'즐거운프로그래밍' 카테고리의 다른 글
| [pandas] pandas APPLYING FUNCTIONS (0) | 2023.11.16 |
|---|---|
| [pandas] pandas 실습예제 3 (0) | 2023.11.16 |
| [pandas] pandas 실습예제 1 (0) | 2023.11.16 |
| [pandas] pandas 데이터 가공 연습하기 (0) | 2023.11.15 |
| [pandas] pandas HTML 웹 자료 읽어온 후 데이터 처리 (0) | 2023.11.15 |