728x90
반응형
import pandas as pd
reviews = pd.read_csv('/content/drive/MyDrive/Notebooks/data/wine-data.csv',index_col=0)
reviews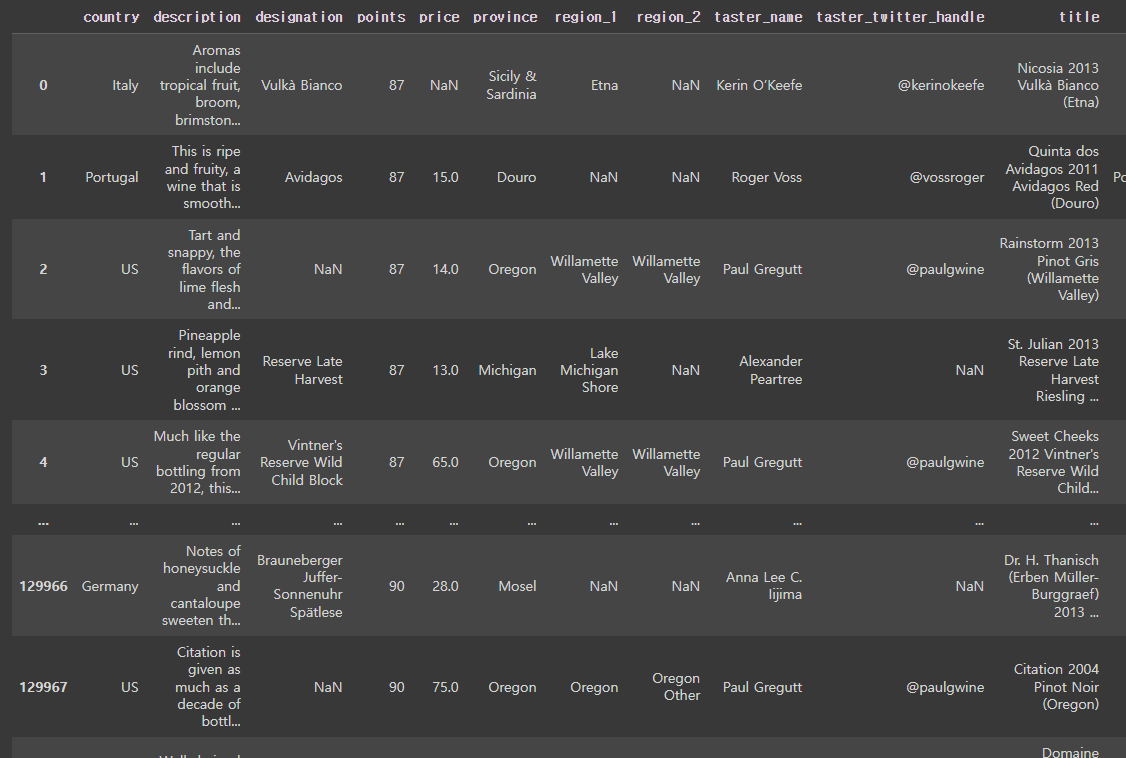
리뷰 데이터프레임에서 points 컬럼의 median 값은?
reviews['points'].median()
나라를 중복되지 않도록 가져와서 countries 변수에 저장하고, 화면에 출력하시오.
countries = reviews['country'].unique()
countries
각 국가별로는 몇개의 리뷰가 있는지, 각국가별 리뷰수를 구하시오.
reviews.groupby('country').size()reviews['country'].value_counts()
리뷰 데이터프레임의 price 컬럼 값에서, price의 평균값을 뺀 값을, centered_price 라고 저장하시오.
centered_price = reviews['price'] - reviews['price'].mean()
centered_price
나는 경제적이므로, 가격대비 포인트가 가장 큰 와인을 사려한다. 해당 와인의 title은?
reviews['가성비'] = reviews['points'] / reviews['price']
reviews
reviews.sort_values('가성비', ascending=False).head(2) # 오름차순 정렬하여 상위 행을 출력함
reviews.loc[reviews['가성비'] == reviews['가성비'].max() , 'title'] # 가성비 컬럼의 max 값을 찾기
reviews.loc[reviews['가성비'] == reviews['가성비'].max() , 'title'][126096]
# 이름이 짤려서 인덱스를 사용해 자세하게 보고 싶을때
reviews.loc[reviews['가성비'] == reviews['가성비'].max() , 'title'].reset_index(drop=True)
# 기존 인덱스 버리기
사람들이 어떤와인을 더 많이 거론했는지 보려한다.
"tropical" 이 들어있는 리뷰의 갯수를 세고, "fruity" 라고 들어있는 리뷰의 갯수를 세어서 판다스 시리즈로 descriptor_counts 변수로 만들어 보자.
reviews['description'][0] # 데이터 액세스 방법 1
reviews.loc[0, 'description'] # 데이터 액세스 방법 2
reviews.iloc[0,1] # 데이터 액세스 방법 3reviews['description'].str.contains('tropical')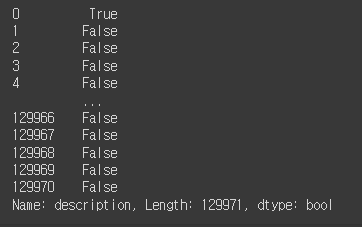
reviews['description'].str.contains('tropical', case=False).sum()
# case=False 대소문자 구분없이 검색reviews['description'].str.lower().str.contains('tropical').sum()
reviews['description'].str.contains('fruity', case=False).sum()reviews['description'].str.lower().str.contains('fruity').sum()
별점 시스템을 만들려고 한다. 따라서 별점에 대한 데이터가 필요하다.
별점은 1,2,3 즉 3개로 만들것이다.
포인트가 95점 이상이면 3점, 85점 이상이면 2점, 나머지는 1점으로 할 것이다. 리뷰데이터를 통해 각 데이터의 별점을 구하시오.
def get_rating(points):
if points >= 95:
return 3
elif points >= 85:
return 2
else:
return 1
reviews['stars'] = reviews['points'].apply(get_rating) # apply : 적용해라
reviews
리뷰의 region_2 컬럼에 데이터가 비어있는 경우에는, 'Unknown'으로 셋팅하자.
reviews['region_2'] = reviews['region_2'].fillna('Unknown')
reviews
포인트로 그룹바이하고 각 포인트별로 몇개의 데이터가 있는지 카운팅하시오
reviews['points'].value_counts().sort_index(ascending=False)
reviews.sort_values(['points','price'] , ascending=[False,True])
포인트별 가격의 최소값을 구해본다
reviews.groupby('points')['price'].min().sort_index(ascending=False)
각 국가별로, 와인 가격의 최소값, 최대값은?
import numpy as np
reviews.groupby('country')['price'].agg([np.min, np.max])
728x90
반응형
'즐거운프로그래밍' 카테고리의 다른 글
| [pandas] pandas SORTING AND ORDERING (0) | 2023.11.16 |
|---|---|
| [pandas] pandas APPLYING FUNCTIONS (0) | 2023.11.16 |
| [pandas] pandas 실습예제 2 (0) | 2023.11.16 |
| [pandas] pandas 실습예제 1 (0) | 2023.11.16 |
| [pandas] pandas 데이터 가공 연습하기 (0) | 2023.11.15 |