728x90
반응형
구글 코랩에 구글 드라이브 마운트 후 csv 파일을 불러옵니다.
import pandas as pd
reviews = pd.read_csv('/content/drive/MyDrive/Notebooks/data/winemag-data.csv',index_col=0)
# index_col = 인덱스로 사용할 컬럼 선택(컬럼 번호로 작성)
reviews
리뷰의 디스크립션 컬럼을 desc 로 저장한다.
desc = reviews['description']
first_description 이라는 변수에는, 디스크립션 컬럼의 첫번째 데이터를 저장한다.
first_description = reviews['description'][0]reviews.loc[0,'description']reviews.iloc[0, 1]
first_row 라는 변수에, 첫번째 리뷰 데이터(행)를 저장한다.
first_row = reviews.loc[0,]
리뷰의 description column 의 값들 중, 첫번째부터 10번째 데이터까지를 first_descriptions 변수에 저장한다.
first_descriptions = reviews['description'][0:9+1]reviews.loc[0:10,'description']reviews.iloc[0:9+1,1]
리뷰에서 인덱스가 1, 2, 3, 5, 8 인 데이터를, sample_reviews 변수에 저장한다.
sample_reviews = reviews.loc[[1,2,3,5,8],]
df 라는 변수에, 다음 조건을 만족하는 데이터프레임을 저장하시오. 인덱스가 0, 1, 10, 100 인 데이터에서, 컬럼이 country, province, region_1, region_2 인 데이터들만 가져와서 저장하시오.
df = reviews.loc[[0,1,10,100],['country','province','region_1','region_2']]
Italy 에서 만들어진 와인에 대해서 italian_wines 이라는 이름으로 데이터프레임을 만드시오.
reviews['country'] == 'Italy'
italian_wines = reviews.loc[reviews['country'] == 'Italy', ]
리뷰점수가 95점 이상이고, Australia와 New Zealand 에서 만들어진 와인에 대한 데이터프레임을 top_oceania_wines 이라는 이름의 변수로 저장.
reviews['points'] >= 95
(reviews['country'] == 'Australia') | (reviews['country'] == 'New Zealand')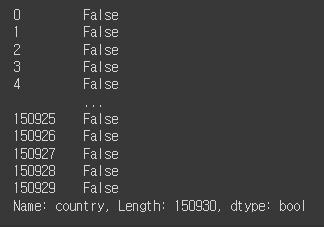
my_filter = (reviews['points'] >= 95) & ((reviews['country'] == 'Australia') | (reviews['country'] == 'New Zealand'))
my_filter
top_oceania_wines = reviews.loc[my_filter, ]
top_oceania_wines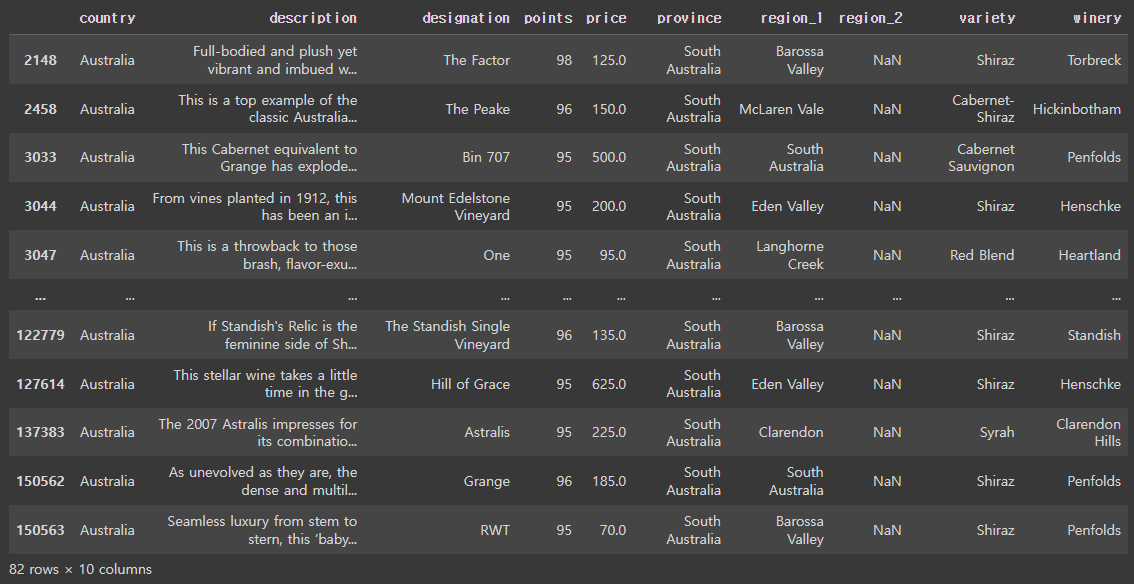
reviews['points'] >=95
reviews['country'].isin(['Australia','New Zealand']) # isin = 안에 있니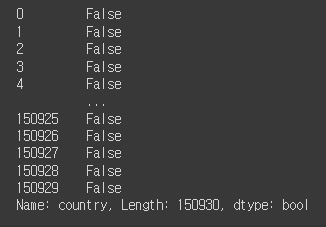
my_filter2 = (reviews['points'] >=95) & (reviews['country'].isin(['Australia','New Zealand']))
reviews.loc[my_filter2]
728x90
반응형
'즐거운프로그래밍' 카테고리의 다른 글
| [pandas] pandas 실습예제 3 (0) | 2023.11.16 |
|---|---|
| [pandas] pandas 실습예제 2 (0) | 2023.11.16 |
| [pandas] pandas 데이터 가공 연습하기 (0) | 2023.11.15 |
| [pandas] pandas HTML 웹 자료 읽어온 후 데이터 처리 (0) | 2023.11.15 |
| [pandas] pandas 파일 읽어온 뒤 데이터 중복 제거와 데이터 처리 예제 (nunique, count, unique, sum, mean, groupby, agg, value_counts) (0) | 2023.11.15 |